常用命令
git branch -a
查看所有的分支,包括本地和远程
有国外开发者在 Quora 提了这个问题:“为什么软件开发周期通常是预期的两三倍?” 并补充问:“这是开发人员的错误? 是管理失误? 是因为做事方法不对, 或者说缺乏好的方法?还是说这就是软件开发流程的特点?” Michael Wolfe 在2012年1月28日给的回复,非常经典,截至我们发布时已有8016个赞。以下是译文。
项目生命周期大致可以分为:初创阶段(协调)->普通成长阶段(质量)->实时监控阶段(预警)->高速发展阶段(高速扩张)->成熟运行阶段(稳定)
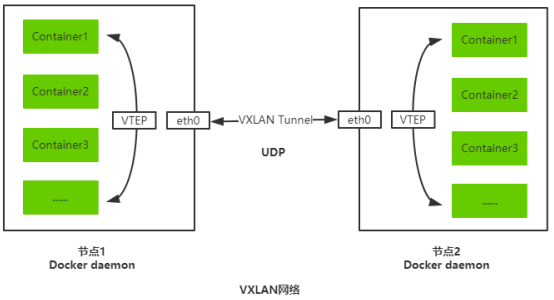
NVE(Network Vritual Endpoint,网络虚拟端点):实现网络虚拟化功能。报文经过NVE封装转换后,NVE间就可基于三层基础网络建立二层虚拟化网络。
VTEP(VXLAN Tunnel Endpoints,VXLAN隧道端点):封装在NVE中,用于VXLAN报文的封装和解封装。
VNI(VXLAN Network Identifier,VXLAN网络标识ID):类似于VLAN ID,用于区分VXLAN段,不同的VXLAN段不能直接二层网络通信。
讲解:
众所周知,HashMap是非线程安全的。而HashMap的线程不安全主要体现在resize时的死循环及使用迭代器时的fail-fast上。
注:本章的代码均基于JDK 1.7.0_67
常用的底层数据结构主要有数组和链表。数组存储区间连续,占用内存较多,寻址容易,插入和删除困难。链表存储区间离散,占用内存较少,寻址困难,插入和删除容易。
HashMap要实现的是哈希表的效果,尽量实现O(1)级别的增删改查。它的具体实现则是同时使用了数组和链表,可以认为最外层是一个数组,数组的每个元素是一个链表的表头。
对于新插入的数据或者待读取的数据,HashMap将Key的哈希值对数组长度取模,结果作为该Entry在数组中的index。在计算机中,取模的代价远高于位操作的代价,因此HashMap要求数组的长度必须为2的N次方。此时将Key的哈希值对2^N-1进行与运算,其效果即与取模等效。HashMap并不要求用户在指定HashMap容量时必须传入一个2的N次方的整数,而是会通过Integer.highestOneBit算出比指定整数大的最小的2^N值,其实现方法如下。
1 | public static int highestOneBit(int i) { |
由于Key的哈希值的分布直接决定了所有数据在哈希表上的分布或者说决定了哈希冲突的可能性,因此为防止糟糕的Key的hashCode实现(例如低位都相同,只有高位不相同,与2^N-1取与后的结果都相同),JDK 1.7的HashMap通过如下方法使得最终的哈希值的二进制形式中的1尽量均匀分布从而尽可能减少哈希冲突。
1 | int h = hashSeed; |
当HashMap的size超过Capacity*loadFactor时,需要对HashMap进行扩容。具体方法是,创建一个新的,长度为原来Capacity两倍的数组,保证新的Capacity仍为2的N次方,从而保证上述寻址方式仍适用。同时需要通过如下transfer方法将原来的所有数据全部重新插入(rehash)到新的数组中。
1 | void transfer(Entry[] newTable, boolean rehash) { |
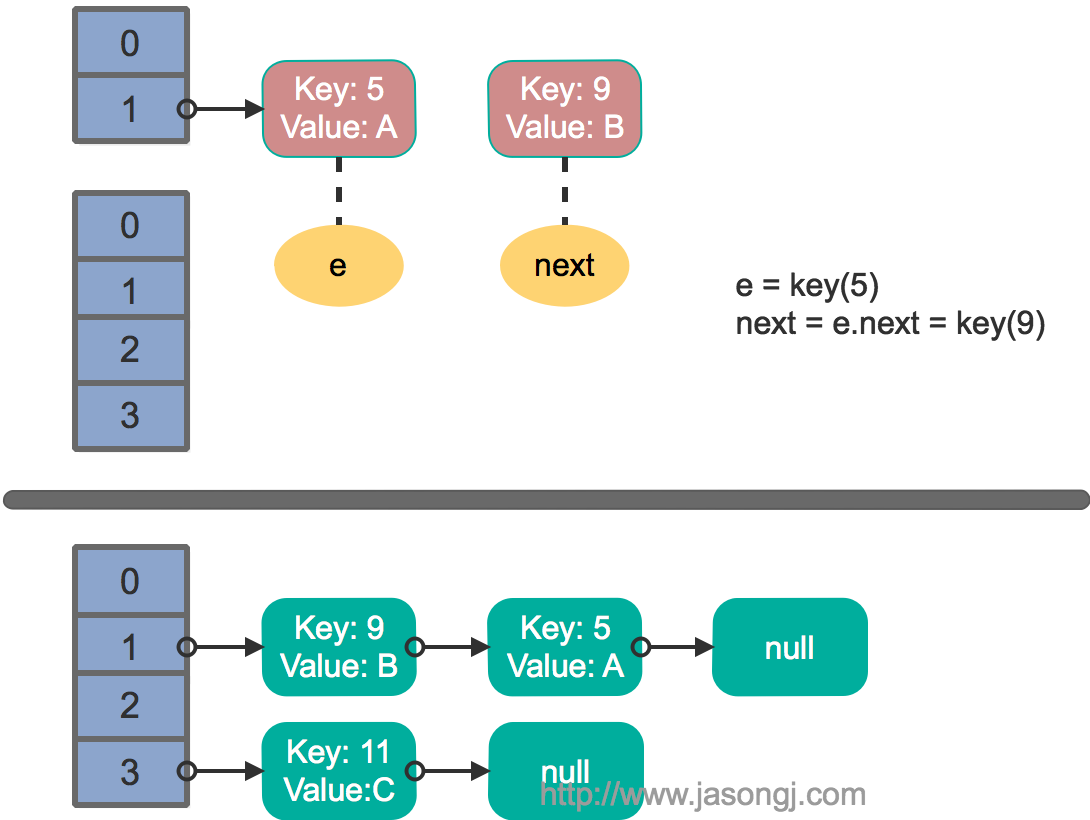
该方法并不保证线程安全,而且在多线程并发调用时,可能出现死循环。其执行过程如下。从步骤2可见,转移时链表顺序反转。
单线程情况下,rehash无问题。下图演示了单线程条件下的rehash过程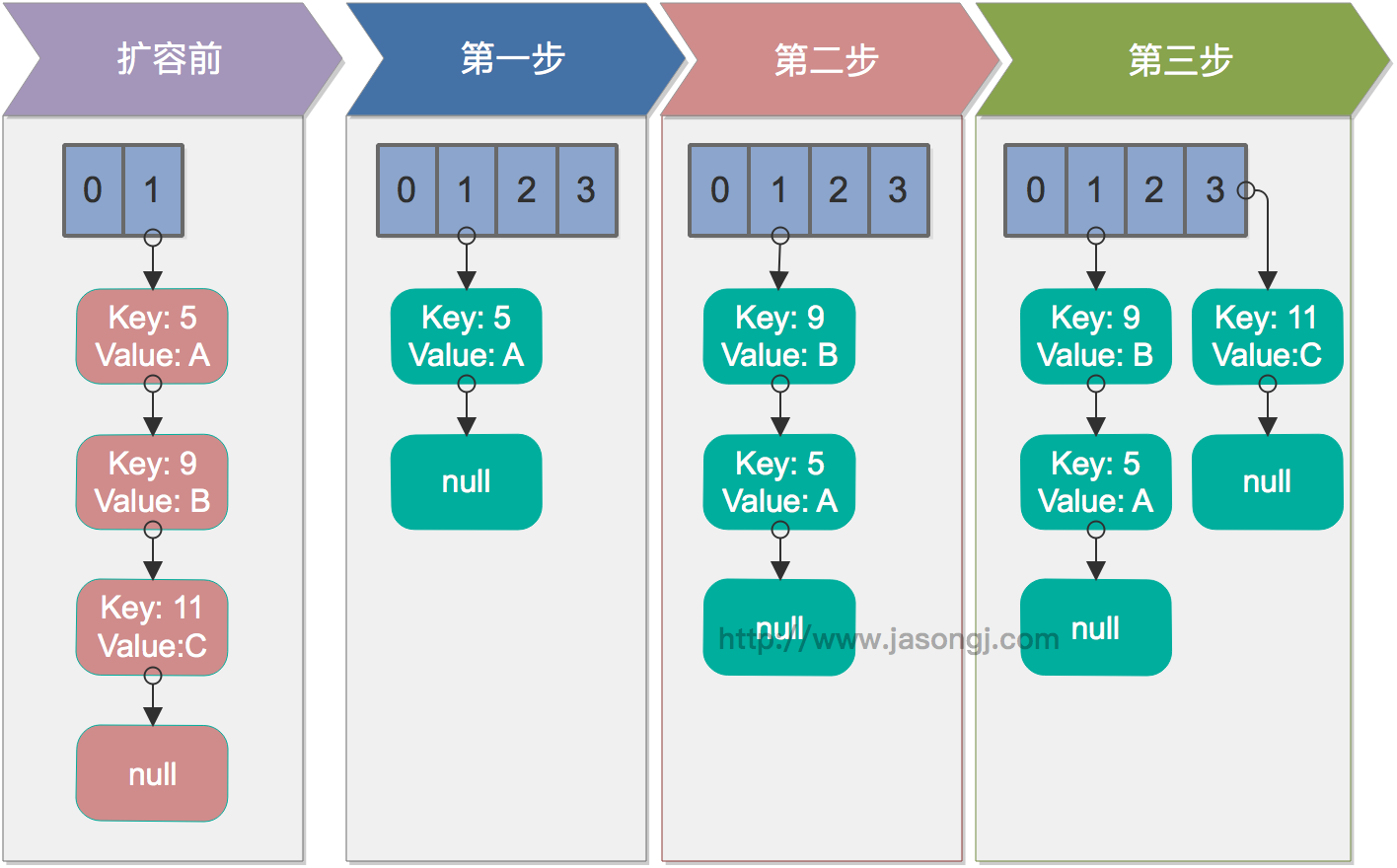
这里假设有两个线程同时执行了put操作并引发了rehash,执行了transfer方法,并假设线程一进入transfer方法并执行完next = e.next后,因为线程调度所分配时间片用完而“暂停”,此时线程二完成了transfer方法的执行。此时状态如下。
接着线程1被唤醒,继续执行第一轮循环的剩余部分
1 | e.next = newTable[1] = null |
结果如下图所示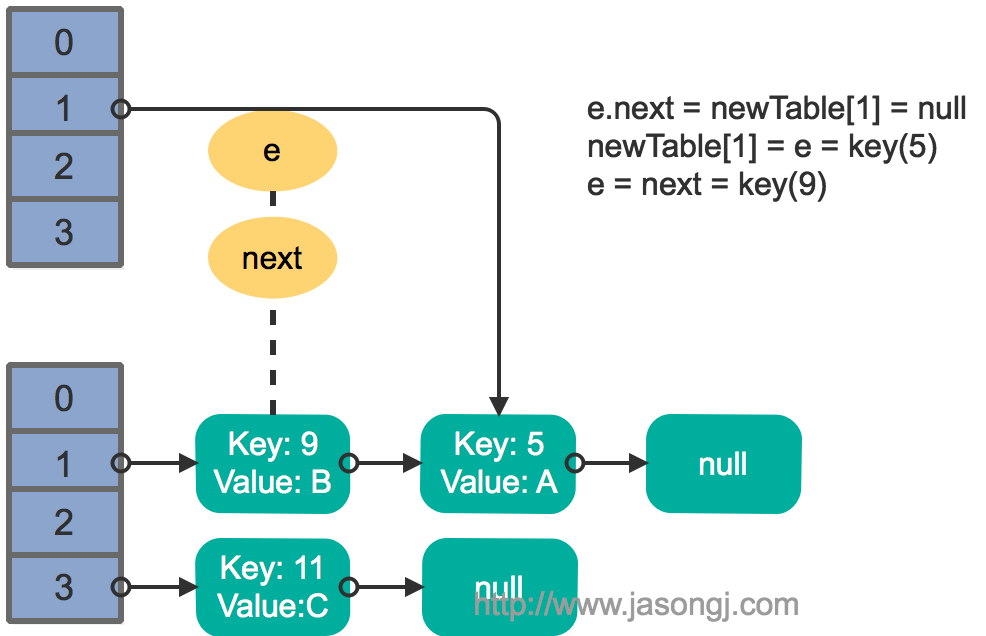
接着执行下一轮循环,结果状态图如下所示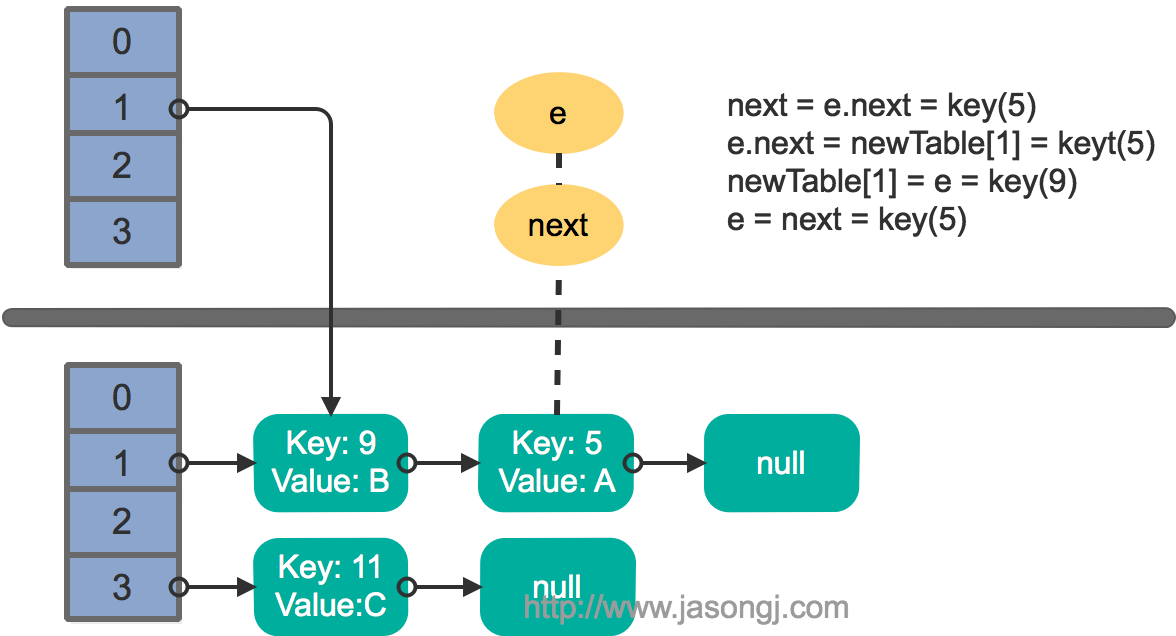
继续下一轮循环,结果状态图如下所示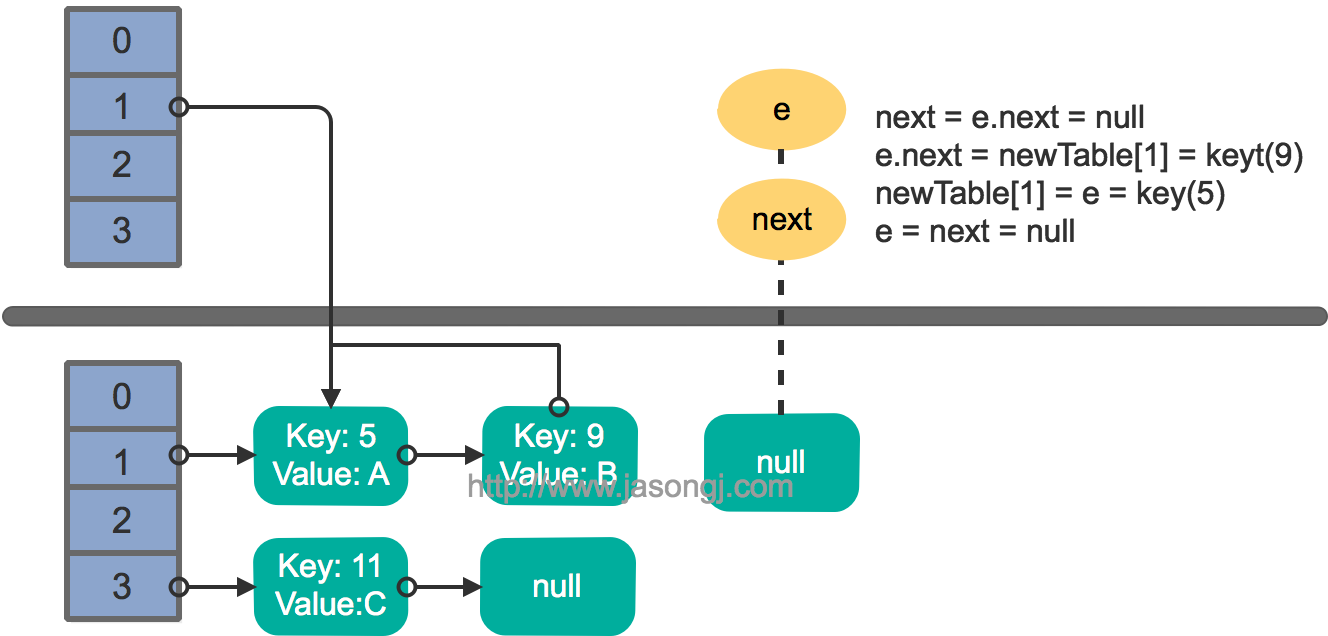
此时循环链表形成,并且key(11)无法加入到线程1的新数组。在下一次访问该链表时会出现死循环。
在使用迭代器的过程中如果HashMap被修改,那么ConcurrentModificationException将被抛出,也即Fail-fast策略。
当HashMap的iterator()方法被调用时,会构造并返回一个新的EntryIterator对象,并将EntryIterator的expectedModCount设置为HashMap的modCount(该变量记录了HashMap被修改的次数)。
1 | HashIterator() { |
在通过该Iterator的next方法访问下一个Entry时,它会先检查自己的expectedModCount与HashMap的modCount是否相等,如果不相等,说明HashMap被修改,直接抛出ConcurrentModificationException。该Iterator的remove方法也会做类似的检查。该异常的抛出意在提醒用户及早意识到线程安全问题。
单线程条件下,为避免出现ConcurrentModificationException,需要保证只通过HashMap本身或者只通过Iterator去修改数据,不能在Iterator使用结束之前使用HashMap本身的方法修改数据。因为通过Iterator删除数据时,HashMap的modCount和Iterator的expectedModCount都会自增,不影响二者的相等性。如果是增加数据,只能通过HashMap本身的方法完成,此时如果要继续遍历数据,需要重新调用iterator()方法从而重新构造出一个新的Iterator,使得新Iterator的expectedModCount与更新后的HashMap的modCount相等。
多线程条件下,可使用Collections.synchronizedMap方法构造出一个同步Map,或者直接使用线程安全的ConcurrentHashMap。
注:本章的代码均基于JDK 1.7.0_67
Java 7中的ConcurrentHashMap的底层数据结构仍然是数组和链表。与HashMap不同的是,ConcurrentHashMap最外层不是一个大的数组,而是一个Segment的数组。每个Segment包含一个与HashMap数据结构差不多的链表数组。整体数据结构如下图所示。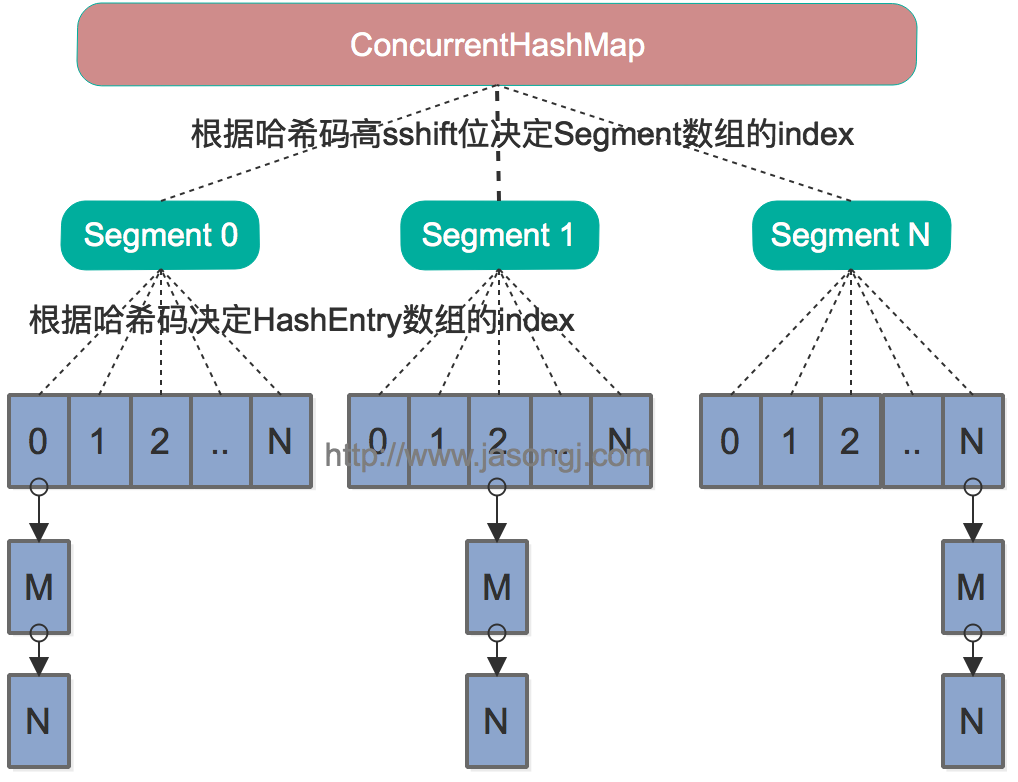
在读写某个Key时,先取该Key的哈希值。并将哈希值的高N位对Segment个数取模从而得到该Key应该属于哪个Segment,接着如同操作HashMap一样操作这个Segment。为了保证不同的值均匀分布到不同的Segment,需要通过如下方法计算哈希值。
1 | private int hash(Object k) { |
同样为了提高取模运算效率,通过如下计算,ssize即为大于concurrencyLevel的最小的2的N次方,同时segmentMask为2^N-1。这一点跟上文中计算数组长度的方法一致。对于某一个Key的哈希值,只需要向右移segmentShift位以取高sshift位,再与segmentMask取与操作即可得到它在Segment数组上的索引。
1 | int sshift = 0; |
Segment继承自ReentrantLock,所以我们可以很方便的对每一个Segment上锁。
对于读操作,获取Key所在的Segment时,需要保证可见性(请参考如何保证多线程条件下的可见性)。具体实现上可以使用volatile关键字,也可使用锁。但使用锁开销太大,而使用volatile时每次写操作都会让所有CPU内缓存无效,也有一定开销。ConcurrentHashMap使用如下方法保证可见性,取得最新的Segment。
1 | Segment<K,V> s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u) |
获取Segment中的HashEntry时也使用了类似方法
1 | HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile |
对于写操作,并不要求同时获取所有Segment的锁,因为那样相当于锁住了整个Map。它会先获取该Key-Value对所在的Segment的锁,获取成功后就可以像操作一个普通的HashMap一样操作该Segment,并保证该Segment的安全性。
同时由于其它Segment的锁并未被获取,因此理论上可支持concurrencyLevel(等于Segment的个数)个线程安全的并发读写。
获取锁时,并不直接使用lock来获取,因为该方法获取锁失败时会挂起(参考可重入锁)。事实上,它使用了自旋锁,如果tryLock获取锁失败,说明锁被其它线程占用,此时通过循环再次以tryLock的方式申请锁。如果在循环过程中该Key所对应的链表头被修改,则重置retry次数。如果retry次数超过一定值,则使用lock方法申请锁。
这里使用自旋锁是因为自旋锁的效率比较高,但是它消耗CPU资源比较多,因此在自旋次数超过阈值时切换为互斥锁。
put、remove和get操作只需要关心一个Segment,而size操作需要遍历所有的Segment才能算出整个Map的大小。一个简单的方案是,先锁住所有Sgment,计算完后再解锁。但这样做,在做size操作时,不仅无法对Map进行写操作,同时也无法进行读操作,不利于对Map的并行操作。
为更好支持并发操作,ConcurrentHashMap会在不上锁的前提逐个Segment计算3次size,如果某相邻两次计算获取的所有Segment的更新次数(每个Segment都与HashMap一样通过modCount跟踪自己的修改次数,Segment每修改一次其modCount加一)相等,说明这两次计算过程中无更新操作,则这两次计算出的总size相等,可直接作为最终结果返回。如果这三次计算过程中Map有更新,则对所有Segment加锁重新计算Size。该计算方法代码如下
1 | public int size() { |
ConcurrentHashMap与HashMap相比,有以下不同点
注:本章的代码均基于JDK 1.8.0_111
Java 7为实现并行访问,引入了Segment这一结构,实现了分段锁,理论上最大并发度与Segment个数相等。Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。其数据结构如下图所示
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。同样为了避免不太好的Key的hashCode设计,它通过如下方法计算得到Key的最终哈希值。不同的是,Java 8的ConcurrentHashMap作者认为引入红黑树后,即使哈希冲突比较严重,寻址效率也足够高,所以作者并未在哈希值的计算上做过多设计,只是将Key的hashCode值与其高16位作异或并保证最高位为0(从而保证最终结果为正整数)。
1 | static final int spread(int h) { |
对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为红黑树,从而提高寻址效率。
对于读操作,由于数组被volatile关键字修饰,因此不用担心数组的可见性问题。同时每个元素是一个Node实例(Java 7中每个元素是一个HashEntry),它的Key值和hash值都由final修饰,不可变更,无须关心它们被修改后的可见性问题。而其Value及对下一个元素的引用由volatile修饰,可见性也有保障。
1 | static class Node<K,V> implements Map.Entry<K,V> { |
对于Key对应的数组元素的可见性,由Unsafe的getObjectVolatile方法保证。
1 | static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { |
put方法和remove方法都会通过addCount方法维护Map的size。size方法通过sumCount获取由addCount方法维护的Map的size。
https://site.ip138.com/raw.Githubusercontent.com/
输入raw.githubusercontent.com
查询IP地址
修改hosts Ubuntu,CentOS及macOS直接在终端输入
sudo vi /etc/hosts
添加以下内容保存即可 (IP地址查询后相应修改,可以ping不同IP的延时 选择最佳IP地址)
1 | # GitHub Start |
创建Docker镜像的方式有三种
最近学习了Dockerfile文件的相关配置,这里做一下简单的总结,并对之前一直感到有些迷惑的CMD和ENTRYPOINT指令做个差异对比。
Dockerfile 由一行行命令语句组成,并且支持以 # 开头的注释行。
一般地,Dockerfile 分为四部分:基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令。
| 四部分 | 指令 |
| :—–| :—- |
| 基础镜像信息 | FROM |
| 维护者信息 | MAINTAINER |
| 镜像操作指令 | RUN、COPY、ADD、EXPOSE等 |
| 容器启动时执行指令 | CMD、ENTRYPOINT |
Dockerfile文件的第一条指令必须是FROM,其后可以是各种镜像的操作指令,最后是CMD或ENTRYPOINT指定容器启动时执行的命令。
指令的一般格式为 INSTRUCTION arguments,指令包括 FROM、MAINTAINER、RUN 等。
格式为 FROM
第一条指令必须为 FROM 指令。并且,如果在同一个Dockerfile中创建多个镜像时,可以使用多个 FROM 指令(每个镜像一次)。
格式为 MAINTAINER
格式为 RUN
前者将在 shell 终端中运行命令,即 /bin/sh -c;后者则使用 exec 执行。指定使用其它终端可以通过第二种方式实现,例如 RUN [“/bin/bash”, “-c”, “echo hello”]。
每条 RUN 指令将在当前镜像基础上执行指定命令,并提交为新的镜像。当命令较长时可以使用 \ 来换行。
指定启动容器时执行的命令,每个 Dockerfile 只能有一条 CMD 命令。如果指定了多条命令,只有最后一条会被执行。
如果用户启动容器时候指定了运行的命令,则会覆盖掉 CMD 指定的命令。
格式为 EXPOSE
告诉 Docker 服务端容器暴露的端口号,供互联系统使用。在启动容器时需要通过 -P,Docker 主机会自动分配一个端口转发到指定的端口。
格式为 ENV
例如:
1 | ENV PG_MAJOR 9.3 |
格式为 ADD
该命令将复制指定的
格式为 COPY
复制本地主机的
当使用本地目录为源目录时,推荐使用 COPY。
ENTRYPOINT
两种格式:
ENTRYPOINT [“executable”, “param1”, “param2”]
ENTRYPOINT command param1 param2(shell中执行)。
配置容器启动后执行的命令,并且不可被 docker run 提供的参数覆盖。
每个 Dockerfile 中只能有一个 ENTRYPOINT,当指定多个时,只有最后一个起效。
格式为 VOLUME [“/data”]。
创建一个可以从本地主机或其他容器挂载的挂载点,一般用来存放数据库和需要保持的数据等。
格式为 USER daemon。
指定运行容器时的用户名或 UID,后续的 RUN 也会使用指定用户。
当服务不需要管理员权限时,可以通过该命令指定运行用户。并且可以在之前创建所需要的用户,例如:RUN groupadd -r postgres && useradd -r -g postgres postgres。要临时获取管理员权限可以使用 gosu,而不推荐 sudo。
格式为 WORKDIR /path/to/workdir。
为后续的 RUN、CMD、ENTRYPOINT 指令配置工作目录。
可以使用多个 WORKDIR 指令,后续命令如果参数是相对路径,则会基于之前命令指定的路径。例如
WORKDIR /a
WORKDIR b
WORKDIR c
RUN pwd
则最终路径为 /a/b/c。
格式为 ONBUILD [INSTRUCTION]。
配置当所创建的镜像作为其它新创建镜像的基础镜像时,所执行的操作指令。
例如,Dockerfile 使用如下的内容创建了镜像 image-A。
[…]
ONBUILD ADD . /app/src
ONBUILD RUN /usr/local/bin/python-build –dir /app/src
[…]
如果基于 image-A 创建新的镜像时,新的Dockerfile中使用 FROM image-A指定基础镜像时,会自动执行 ONBUILD 指令内容,等价于在后面添加了两条指令。
FROM image-A #Automatically run the followingADD . /app/srcRUN /usr/local/bin/python-build –dir /app/src
使用 ONBUILD 指令的镜像,推荐在标签中注明,例如 ruby:1.9-onbuild。
编写完Dockerfile文件后,通过运行docker build命令来创建自定义的镜像。Docker build命令格式如下:
docker build [options]
该命令将读取指定路径下(包括子目录)的 Dockerfile,并将该路径下所有内容发送给 Docker 服务端,由服务端来创建镜像。因此一般建议放置 Dockerfile 的目录为空目录。也可以通过 .dockerignore 文件(每一行添加一条匹配模式)来让 Docker 忽略路径下的目录和文件。
例如下面使用Dockerfile样例来创建了镜像test:0.0.1,其中-t选项用来指定镜像的tag。Dockerfile文件内容如下:
1 | FROM ubuntu:14.04 |
下面运行docker build命令生成镜像test:0.0.1,
1 | lienhua34@test$ sudo docker build -t test:0.0.1 . |
然后启动该镜像的容器来查看结果,
1 | lienhua34@test$ sudo docker images |
Dockerfile文件的每条指令生成镜像的一层(注:一个镜像不能超过127层)。Dockerfile中的指令被一条条地执行。每一步都创建一个新的容器,在容器中执行指令并提交修改。当所有指令执行完毕后,返回最终的镜像id。
CMD指令和ENTRYPOINT指令的作用都是为镜像指定容器启动后的命令,那么它们两者之间有什么各自的优点呢?
为了更好地对比CMD指令和ENTRYPOINT指令的差异,我们这里再列一下这两个指令的说明,
CMD
支持三种格式
CMD [“executable”,”param1”,”param2”] 使用 exec 执行,推荐方式;
CMD command param1 param2 在 /bin/sh 中执行,提供给需要交互的应用;
CMD [“param1”,”param2”] 提供给 ENTRYPOINT 的默认参数;
指定启动容器时执行的命令,每个 Dockerfile 只能有一条 CMD 命令。如果指定了多条命令,只有最后一条会被执行。
如果用户启动容器时候指定了运行的命令,则会覆盖掉 CMD 指定的命令。
ENTRYPOINT
两种格式:
ENTRYPOINT [“executable”, “param1”, “param2”]
ENTRYPOINT command param1 param2(shell中执行)。
配置容器启动后执行的命令,并且不可被 docker run 提供的参数覆盖。
每个 Dockerfile 中只能有一个 ENTRYPOINT,当指定多个时,只有最后一个起效。
从上面的说明,我们可以看到有两个共同点:
都可以指定shell或exec函数调用的方式执行命令;
当存在多个CMD指令或ENTRYPOINT指令时,只有最后一个生效;
而它们有如下差异:
差异1:CMD指令指定的容器启动时命令可以被docker run指定的命令覆盖,而ENTRYPOINT指令指定的命令不能被覆盖,而是将docker run指定的参数当做ENTRYPOINT指定命令的参数。
差异2:CMD指令可以为ENTRYPOINT指令设置默认参数,而且可以被docker run指定的参数覆盖;
下面分别对上面两个差异点进行详细说明,
CMD指令指定的容器启动时命令可以被docker run指定的命令覆盖;而ENTRYPOINT指令指定的命令不能被覆盖,而是将docker run指定的参数当做ENTRYPOINT指定命令的参数。
下面有个命名为startup的可执行shell脚本,其功能就是输出命令行参数而已。内容如下所示,
1 |
|
通过CMD指定容器启动时命令:
现在我们新建一个Dockerfile文件,其将startup脚本拷贝到容器的/opt目录下,并通过CMD指令指定容器启动时运行该startup脚本。其内容如下,
1 | FROM ubuntu:14.04 |
然后我们通过运行docker build命令生成test:latest镜像,
1 | lienhua34@test$ sudo docker build -t test . |
然后使用docker run启动两个test:latest镜像的容器,第一个docker run命令没有指定容器启动时命令,第二个docker run命令指定了容器启动时的命令为“/bin/bash -c ‘echo Hello’”,
1 | lienhua34@test$ sudo docker run -ti --rm=true test |
从上面运行结果可以看到,docker run命令启动容器时指定的运行命令覆盖了Dockerfile文件中CMD指令指定的命令。
通过ENTRYPOINT指定容器启动时命令:
将上面的Dockerfile中的CMD替换成ENTRYPOINT,内容如下所示,
1 | FROM ubuntu:14.04 |
同样,通过运行docker build生成test:latest镜像,
1 | lienhua34@test$ sudo docker build -t test . |
然后使用docker run启动两个test:latest镜像的容器,第一个docker run命令没有指定容器启动时命令,第二个docker run命令指定了容器启动时的命令为“/bin/bash -c ‘echo Hello’”,
1 | lienhua34@test$ sudo docker run -ti --rm=true test |
通过上面的运行结果可以看出,docker run命令指定的容器运行命令不能覆盖Dockerfile文件中ENTRYPOINT指令指定的命令,反而被当做参数传递给ENTRYPOINT指令指定的命令。
CMD指令可以为ENTRYPOINT指令设置默认参数,而且可以被docker run指定的参数覆盖;
同样使用上面的startup脚本。编写Dockerfile,内容如下所示,
1 | FROM ubuntu:14.04 |
运行docker build命令生成test:latest镜像,
1 | lienhua34@test$ sudo docker build -t test . |
下面运行docker run启动两个test:latest镜像的容器,第一条docker run命令没有指定参数,第二条docker run命令指定了参数arg3,其运行结果如下,
1 | lienhua34@test$ sudo docker run -ti --rm=true test |
从上面第一个容器的运行结果可以看出CMD指令为ENTRYPOINT指令设置了默认参数;从第二个容器的运行结果看出,docker run命令指定的参数覆盖了CMD指令指定的参数。
CMD指令为ENTRYPOINT指令提供默认参数是基于镜像层次结构生效的,而不是基于是否在同个Dockerfile文件中。意思就是说,如果Dockerfile指定基础镜像中是ENTRYPOINT指定的启动命令,则该Dockerfile中的CMD依然是为基础镜像中的ENTRYPOINT设置默认参数。
例如,我们有如下一个Dockerfile文件,
1 | FROM ubuntu:14.04 |
通过运行docker build命令生成test:0.0.1镜像,然后创建该镜像的一个容器,查看运行结果,
1 | lienhua34@test$ sudo docker build -t test:0.0.1 . |
下面新建一个Dockerfile文件,基础镜像是刚生成的test:0.0.1,通过CMD指定要通过echo打印字符串“in test:0.0.2”。文件内容如下所示,
1 | FROM test:0.0.1 |
运行docker build命令生成test:0.0.2镜像,然后通过运行docker run启动一个test:0.0.2镜像的容器来查看结果,
1 | lienhua34@test$ sudo docker build -t test:0.0.2 . |
从上面结果可以看到,镜像test:0.0.2启动的容器运行时并不是打印字符串”in test:0.0.2”,而是将CMD指令指定的命令当做基础镜像test:0.0.1中ENTRYPOINT指定的运行脚本startup的参数。
1 | <properties> |
serverId : nex-alan-release
在maven的配置文件settings.xml中配置用户名和密码:
imageName
需要加 标签, 不然-DpushImage 会报错,找不到镜像