在上一篇文章详细的介绍了Gateway的Predict,Predict决定了请求由哪一个路由处理,在路由处理之前,需要经过“pre”类型的过滤器处理,处理返回响应之后,可以由“post”类型的过滤器处理。
filter的作用和生命周期 由filter工作流程点,可以知道filter有着非常重要的作用,在“pre”类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等,在“post”类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流量监控等。首先需要弄清一点为什么需要网关这一层,这就不得不说下filter的作用了。
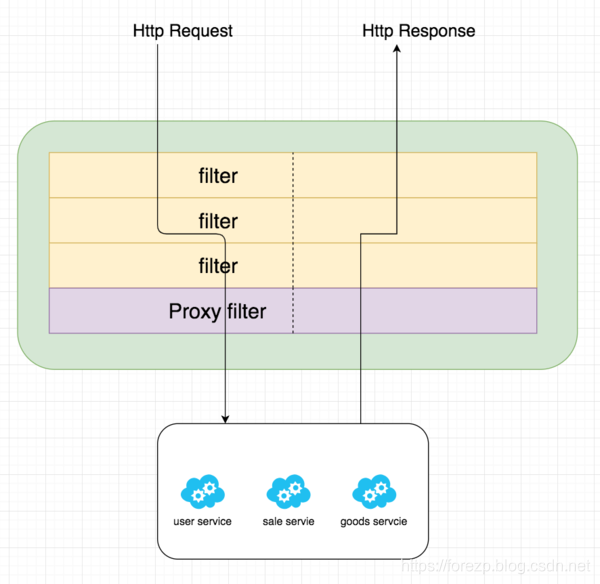
作用 当我们有很多个服务时,比如下图中的user-service、goods-service、sales-service等服务,客户端请求各个服务的Api时,每个服务都需要做相同的事情,比如鉴权、限流、日志输出等。
对于这样重复的工作,有没有办法做的更好,答案是肯定的。在微服务的上一层加一个全局的权限控制、限流、日志输出的Api Gatewat服务,然后再将请求转发到具体的业务服务层。这个Api Gateway服务就是起到一个服务边界的作用,外接的请求访问系统,必须先通过网关层。
生命周期 Spring Cloud Gateway同zuul类似,有“pre”和“post”两种方式的filter。客户端的请求先经过“pre”类型的filter,然后将请求转发到具体的业务服务,比如上图中的user-service,收到业务服务的响应之后,再经过“post”类型的filter处理,最后返回响应到客户端。
与zuul不同的是,filter除了分为“pre”和“post”两种方式的filter外,在Spring Cloud Gateway中,filter从作用范围可分为另外两种,一种是针对于单个路由的gateway filter,它在配置文件中的写法同predict类似;另外一种是针对于所有路由的global gateway filer。现在从作用范围划分的维度来讲解这两种filter。
gateway filter 过滤器允许以某种方式修改传入的HTTP请求或传出的HTTP响应。过滤器可以限定作用在某些特定请求路径上。 Spring Cloud Gateway包含许多内置的GatewayFilter工厂。
GatewayFilter工厂同上一篇介绍的Predicate工厂类似,都是在配置文件application.yml中配置,遵循了约定大于配置的思想,只需要在配置文件配置GatewayFilter Factory的名称,而不需要写全部的类名,比如AddRequestHeaderGatewayFilterFactory只需要在配置文件中写AddRequestHeader,而不是全部类名。在配置文件中配置的GatewayFilter Factory最终都会相应的过滤器工厂类处理。
Spring Cloud Gateway 内置的过滤器工厂一览表如下:
现在挑几个常见的过滤器工厂来讲解,每一个过滤器工厂在官方文档都给出了详细的使用案例,如果不清楚的还可以在org.springframework.cloud.gateway.filter.factory看每一个过滤器工厂的源码。
创建工程,引入相关的依赖,包括spring boot 版本2.0.5,spring Cloud版本Finchley,gateway依赖如下:
1 2 3 4 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-gateway</artifactId > </dependency >
在工程的配置文件中,加入以下的配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 server: port: 8081 spring: profiles: active: add_request_header_route --- spring: cloud: gateway: routes: - id: add_request_header_route uri: http://httpbin.org:80/get filters: - AddRequestHeader=X-Request-Foo, Bar predicates: - After=2017-01-20T17:42:47.789-07:00[America/Denver] profiles: add_request_header_route
在上述的配置中,工程的启动端口为8081,配置文件为add_request_header_route,在add_request_header_route配置中,配置了roter的id为add_request_header_route,路由地址为http://httpbin.org:80/get,该router有AfterPredictFactory,有一个filter为AddRequestHeaderGatewayFilterFactory(约定写成AddRequestHeader),AddRequestHeader过滤器工厂会在请求头加上一对请求头,名称为X-Request-Foo,值为Bar。为了验证AddRequestHeaderGatewayFilterFactory是怎么样工作的,查看它的源码,AddRequestHeaderGatewayFilterFactory的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class AddRequestHeaderGatewayFilterFactory extends AbstractNameValueGatewayFilterFactory @Override public GatewayFilter apply (NameValueConfig config) return (exchange, chain) -> { ServerHttpRequest request = exchange.getRequest().mutate() .header(config.getName(), config.getValue()) .build(); return chain.filter(exchange.mutate().request(request).build()); }; } }
由上面的代码可知,根据旧的ServerHttpRequest创建新的 ServerHttpRequest ,在新的ServerHttpRequest加了一个请求头,然后创建新的 ServerWebExchange ,提交过滤器链继续过滤。
启动工程,通过curl命令来模拟请求:
最终显示了从 http://httpbin.org:80/get得到了请求,响应如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "args" : {}, "headers" : { "Accept" : "*/*" , "Connection" : "close" , "Forwarded" : "proto=http;host=\"localhost:8081\";for=\"0:0:0:0:0:0:0:1:56248\"" , "Host" : "httpbin.org" , "User-Agent" : "curl/7.58.0" , "X-Forwarded-Host" : "localhost:8081" , "X-Request-Foo" : "Bar" }, "origin" : "0:0:0:0:0:0:0:1, 210.22.21.66" , "url" : "http://localhost:8081/get" }
可以上面的响应可知,确实在请求头中加入了X-Request-Foo这样的一个请求头,在配置文件中配置的AddRequestHeader过滤器工厂生效。
跟AddRequestHeader过滤器工厂类似的还有AddResponseHeader过滤器工厂,在此就不再重复。
RewritePath GatewayFilter Factory 在Nginx服务启中有一个非常强大的功能就是重写路径,Spring Cloud Gateway默认也提供了这样的功能,这个功能是Zuul没有的。在配置文件中加上以下的配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 spring: profiles: active: rewritepath_route --- spring: cloud: gateway: routes: - id: rewritepath_route uri: https://blog.csdn.net predicates: - Path=/foo/** filters: - RewritePath=/foo/(?<segment>.*), /$\{segment} profiles: rewritepath_route
上面的配置中,所有的/foo/*开始的路径都会命中配置的router,并执行过滤器的逻辑,在本案例中配置了RewritePath过滤器工厂,此工厂将/foo/(?. )重写为{segment},然后转发到https://blog.csdn.net。比如在网页上请求localhost:8081/foo/forezp,此时会将请求转发到https://blog.csdn.net/forezp的页面,比如在网页上请求localhost:8081/foo/forezp/1,页面显示404,就是因为不存在https://blog.csdn.net/forezp/1这个页面。
自定义过滤器 Spring Cloud Gateway内置了19种强大的过滤器工厂,能够满足很多场景的需求,那么能不能自定义自己的过滤器呢,当然是可以的。在spring Cloud Gateway中,过滤器需要实现GatewayFilter和Ordered2个接口。写一个RequestTimeFilter,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class RequestTimeFilter implements GatewayFilter , Ordered private static final Log log = LogFactory.getLog(GatewayFilter.class ) ; private static final String REQUEST_TIME_BEGIN = "requestTimeBegin" ; @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { exchange.getAttributes().put(REQUEST_TIME_BEGIN, System.currentTimeMillis()); return chain.filter(exchange).then( Mono.fromRunnable(() -> { Long startTime = exchange.getAttribute(REQUEST_TIME_BEGIN); if (startTime != null ) { log.info(exchange.getRequest().getURI().getRawPath() + ": " + (System.currentTimeMillis() - startTime) + "ms" ); } }) ); } @Override public int getOrder () return 0 ; } }
在上面的代码中,Ordered中的int getOrder()方法是来给过滤器设定优先级别的,值越大则优先级越低。还有有一个filterI(exchange,chain)方法,在该方法中,先记录了请求的开始时间,并保存在ServerWebExchange中,此处是一个“pre”类型的过滤器,然后再chain.filter的内部类中的run()方法中相当于”post”过滤器,在此处打印了请求所消耗的时间。然后将该过滤器注册到router中,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Bean public RouteLocator customerRouteLocator (RouteLocatorBuilder builder) return builder.routes() .route(r -> r.path("/customer/**" ) .filters(f -> f.filter(new RequestTimeFilter()) .addResponseHeader("X-Response-Default-Foo" , "Default-Bar" )) .uri("http://httpbin.org:80/get" ) .order(0 ) .id("customer_filter_router" ) ) .build(); }
重启程序,通过curl命令模拟请求:
1 curl localhost:8081/customer/123
在程序的控制台输出一下的请求信息的日志:
1 2018-11-16 15:02:20.177 INFO 20488 --- [ctor-http-nio-3] o.s.cloud.gateway.filter.GatewayFilter : /customer/123: 152ms
自定义过滤器工厂 在上面的自定义过滤器中,有没有办法自定义过滤器工厂类呢?这样就可以在配置文件中配置过滤器了。现在需要实现一个过滤器工厂,在打印时间的时候,可以设置参数来决定是否打印请参数。查看GatewayFilterFactory的源码,可以发现GatewayFilterfactory的层级如下:
过滤器工厂的顶级接口是GatewayFilterFactory,我们可以直接继承它的两个抽象类来简化开发AbstractGatewayFilterFactory和AbstractNameValueGatewayFilterFactory,这两个抽象类的区别就是前者接收一个参数(像StripPrefix和我们创建的这种),后者接收两个参数(像AddResponseHeader)。
过滤器工厂的顶级接口是GatewayFilterFactory,有2个两个较接近具体实现的抽象类,分别为AbstractGatewayFilterFactory和AbstractNameValueGatewayFilterFactory,这2个类前者接收一个参数,比如它的实现类RedirectToGatewayFilterFactory;后者接收2个参数,比如它的实现类AddRequestHeaderGatewayFilterFactory类。现在需要将请求的日志打印出来,需要使用一个参数,这时可以参照RedirectToGatewayFilterFactory的写法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public class RequestTimeGatewayFilterFactory extends AbstractGatewayFilterFactory <RequestTimeGatewayFilterFactory .Config > private static final Log log = LogFactory.getLog(GatewayFilter.class ) ; private static final String REQUEST_TIME_BEGIN = "requestTimeBegin" ; private static final String KEY = "withParams" ; @Override public List<String> shortcutFieldOrder () return Arrays.asList(KEY); } public RequestTimeGatewayFilterFactory () super (Config.class ) ; } @Override public GatewayFilter apply (Config config) return (exchange, chain) -> { exchange.getAttributes().put(REQUEST_TIME_BEGIN, System.currentTimeMillis()); return chain.filter(exchange).then( Mono.fromRunnable(() -> { Long startTime = exchange.getAttribute(REQUEST_TIME_BEGIN); if (startTime != null ) { StringBuilder sb = new StringBuilder(exchange.getRequest().getURI().getRawPath()) .append(": " ) .append(System.currentTimeMillis() - startTime) .append("ms" ); if (config.isWithParams()) { sb.append(" params:" ).append(exchange.getRequest().getQueryParams()); } log.info(sb.toString()); } }) ); }; } public static class Config private boolean withParams; public boolean isWithParams () return withParams; } public void setWithParams (boolean withParams) this .withParams = withParams; } } }
在上面的代码中 apply(Config config)方法内创建了一个GatewayFilter的匿名类,具体的实现逻辑跟之前一样,只不过加了是否打印请求参数的逻辑,而这个逻辑的开关是config.isWithParams()。静态内部类类Config就是为了接收那个boolean类型的参数服务的,里边的变量名可以随意写,但是要重写List shortcutFieldOrder()这个方法。
需要注意的是,在类的构造器中一定要调用下父类的构造器把Config类型传过去,否则会报ClassCastException
最后,需要在工程的启动文件Application类中,向Srping Ioc容器注册RequestTimeGatewayFilterFactory类的Bean。
1 2 3 4 @Bean public RequestTimeGatewayFilterFactory elapsedGatewayFilterFactory () return new RequestTimeGatewayFilterFactory(); }
然后可以在配置文件中配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 spring: profiles: active: elapse_route --- spring: cloud: gateway: routes: - id: elapse_route uri: http://httpbin.org:80/get filters: - RequestTime=false predicates: - After=2017-01-20T17:42:47.789-07:00[America/Denver] profiles: elapse_route
启动工程,在浏览器上访问localhost:8081?name=forezp,可以在控制台上看到,日志输出了请求消耗的时间和请求参数。
global filter Spring Cloud Gateway根据作用范围划分为GatewayFilter和GlobalFilter,二者区别如下:
GatewayFilter : 需要通过spring.cloud.routes.filters 配置在具体路由下,只作用在当前路由上或通过spring.cloud.default-filters配置在全局,作用在所有路由上
GlobalFilter : 全局过滤器,不需要在配置文件中配置,作用在所有的路由上,最终通过GatewayFilterAdapter包装成GatewayFilterChain可识别的过滤器,它为请求业务以及路由的URI转换为真实业务服务的请求地址的核心过滤器,不需要配置,系统初始化时加载,并作用在每个路由上。
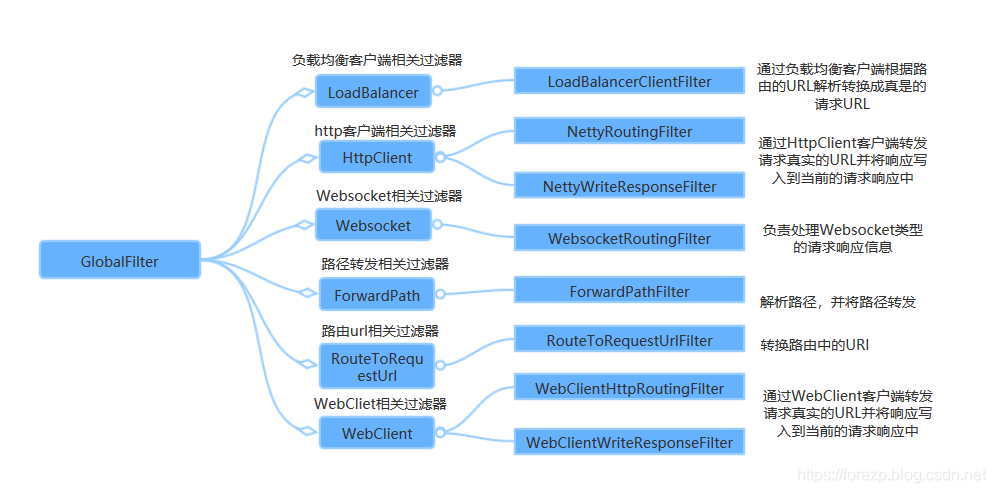
Spring Cloud Gateway框架内置的GlobalFilter如下:
上图中每一个GlobalFilter都作用在每一个router上,能够满足大多数的需求。但是如果遇到业务上的定制,可能需要编写满足自己需求的GlobalFilter。在下面的案例中将讲述如何编写自己GlobalFilter,该GlobalFilter会校验请求中是否包含了请求参数“token”,如何不包含请求参数“token”则不转发路由,否则执行正常的逻辑。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class TokenFilter implements GlobalFilter , Ordered Logger logger=LoggerFactory.getLogger( TokenFilter.class ) ; @Override public Mono<Void> filter (ServerWebExchange exchange, GatewayFilterChain chain) String token = exchange.getRequest().getQueryParams().getFirst("token" ); if (token == null || token.isEmpty()) { logger.info( "token is empty..." ); exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED); return exchange.getResponse().setComplete(); } return chain.filter(exchange); } @Override public int getOrder () return -100 ; } }
在上面的TokenFilter需要实现GlobalFilter和Ordered接口,这和实现GatewayFilter很类似。然后根据ServerWebExchange获取ServerHttpRequest,然后根据ServerHttpRequest中是否含有参数token,如果没有则完成请求,终止转发,否则执行正常的逻辑。
然后需要将TokenFilter在工程的启动类中注入到Spring Ioc容器中,代码如下:
1 2 3 4 @Bean public TokenFilter tokenFilter () return new TokenFilter(); }
启动工程,使用curl命令请求:
1 curl localhost:8081/customer/123
可以看到请没有被转发,请求被终止,并在控制台打印了如下日志:
1 2018-11-16 15:30:13.543 INFO 19372 --- [ctor-http-nio-2] gateway.TokenFilter : token is empty...
上面的日志显示了请求进入了没有传“token”的逻辑。
总结 本篇文章讲述了Spring Cloud Gateway中的过滤器,包括GatewayFilter和GlobalFilter。从官方文档的内置过滤器讲起,然后讲解自定义GatewayFilter、GatewayFilterFactory以及自定义的GlobalFilter。有很多内置的过滤器并没有讲述到,比如限流过滤器,这个我觉得是比较重要和大家关注的过滤器,将在之后的文章讲述。
更多阅读 史上最简单的 SpringCloud 教程汇总
SpringBoot教程汇总