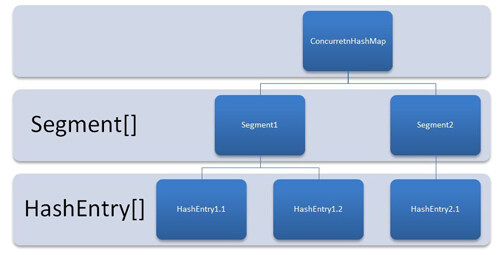
ConcurrentHashMap
是线程安全的。
Put方法,首先是对key.hashCode进行hash操作,得到hash值。然后获取对应的segment对象,接着调用Segment对象的put方法完成当前操作。当调用put方法时,首先lock操作,完成操作后再释放锁。
Semaphore
可以控制某资源同时被访问的个数。例如连接池中通常要控制创建连接的个数。
tryAcquire方法,获得锁
release方法,释放锁
CountdownLatch
闭锁,确保一个服务不会开始,直到它依赖的其他服务都已近开始,它允许一个或多个线程,等待一个事件集的发生。
通过减计数的方式,控制多个线程同时开始某个动作。当计数为0时,await后的代码才会被执行。
提供await()和countDown()两个方法。
CyclicBarrier
CyclicBarrier中的await方法会对count值减1,并阻塞当前线程(java.util.concurrent.locks.Condition.await()),如果count==0时先执行CyclicBarrier内部的Runnable任务(java.lang.Runnable.run()),然后唤醒所有阻塞的线程(java.util.concurrent.locks.Condition.signalAll()),count恢复初始值(可以进入下一轮循环)。
与CountdownLatch不同的是,它可以循环重用。
1 | import java.util.concurrent.CyclicBarrier; |
结果:
1 | Worker's waiting |
AtomicInteger
原子操作,线程安全。之前如果多线程累计计数,需要通过锁控制。
IncrementAndGet方法,关键是调用了compareAndSwap方法,是native方法,基于cpu的CAS原语来实现的。简单原理是由cpu比较内存位置上的值是否为当前值,如果是换成新值,否则返回false
ThreadPoolExecutor
提供线程池服务,
1 | ThreadPoolExecutor(int corePoolSize, |
1 | corePoolSize: 线程池维护线程的最少数量 |
block queue有以下几种实现:
- ArrayBlockingQueue:有界的数组队列
- LinkedBlockingQueue:可支持有界、无界的队列,使用链表实现
- PriorityBlockingQueue:优先队列,可对任务排序
- SynchronousQueue:队列长度为1的队列,和Array有点区别就是:client 线程提交到 block queue会是一个阻塞过程,直到有一个消费线程连接上来poll task
RejectExecutionHandler是针对任务无法处理时的一些自我保护处理:
- Reject 直接抛出Reject exception
- Discard 直接忽略该runnable,不建议使用
- DiscardOldest 丢弃最早入队列的任务
- CallerRuns 直接让原先的client thread做为消费线程,象同步调用方式一样,自己来执行。

如何确定最大线程数?
确定线程数首先需要考虑到系统可用的处理器核心数:
Runtime.getRuntime().availableProcessors();
应用程序最小线程数应该等于可用的处理器核数。
如果所有的任务都是计算密集型的,则创建处理器可用核心数这么多个线程就可以了,这样已经充分利用了处理器,也就是让它以最大火力不停进行计算。创建更多的线程对于程序性能反而是不利的,因为多个线程间频繁进行上下文切换对于程序性能损耗较大。
如果任务都是IO密集型的,那我们就需要创建比处理器核心数大几倍数量的线程。为何?当一个任务执行IO操作时,线程将被阻塞,于是处理器可以立即进行上下文切换以便处理其他就绪线程。如果我们只有处理器核心数那么多个线程的话,即使有待执行的任务也无法调度处理了。
因此,线程数与我们每个任务处于阻塞状态的时间比例相关。加入任务有50%时间处于阻塞状态,那程序所需线程数是处理器核心数的两倍。我们可以计算出程序所需的线程数,公式如下:
线程数=CPU可用核心数/(1 - 阻塞系数),其中阻塞系数在在0到1范围内。
计算密集型程序的阻塞系数为0,IO密集型程序的阻塞系数接近1。
确定阻塞系数,我们可以先试着猜测,或者采用一些性能分析工具或java.lang.management API 来确定线程花在系统IO上的时间与CPU密集任务所耗的时间比值。
Executors
工具类,提供大量管理线程执行器的工厂方法。
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
1
2
3
4
5public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
} - newFixedThreadPool(int) ,创建固定大小的线程池
1
2
3
4
5public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
} - newSingleThreadPool(),创建大小为1的线程池,同一时刻执行的task只有一个,其它的都放在阻塞队列中。
1
2
3
4
5
6public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
} - newScheduledThreadPool(int),适用于一些需要定时或延迟的任务。与Timer的区别:
- Timer是单线程,一旦一个task执行慢,将会影响其它任务。另外如果抛出异常,其它任务也不再执行。
- ScheduledThreadPoolExecutor可执行callable的task,执行完毕后得到执行结果。任务队列是基于DelayedWorkQueue实现,将有新task加入时,会按执行时间排序。
1
2
3
4
5
6
7
8public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
newWorkStealingPool:jdk1.8新增,创建持有足够线程的线程池来支持给定的并行级别,并通过使用多个队列,减少竞争,它需要穿一个并行级别的参数,如果不传,则被设定为默认的CPU数量。
1
2
3
4
5public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool (Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}自定义线程池
以下是自定义线程池,使用了有界队列,自定义ThreadFactory和拒绝策略的demo:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74public class ThreadTest {
public static void main(String[] args) throws InterruptedException, IOException {
int corePoolSize = 2;
int maximumPoolSize = 4;
long keepAliveTime = 10;
TimeUnit unit = TimeUnit.SECONDS;
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2);
ThreadFactory threadFactory = new NameTreadFactory();
RejectedExecutionHandler handler = new MyIgnorePolicy();
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit,
workQueue, threadFactory, handler);
executor.prestartAllCoreThreads(); // 预启动所有核心线程
for (int i = 1; i <= 10; i++) {
MyTask task = new MyTask(String.valueOf(i));
executor.execute(task);
}
System.in.read(); //阻塞主线程
}
static class NameTreadFactory implements ThreadFactory {
private final AtomicInteger mThreadNum = new AtomicInteger(1);
public Thread newThread(Runnable r) {
Thread t = new Thread(r, "my-thread-" + mThreadNum.getAndIncrement());
System.out.println(t.getName() + " has been created");
return t;
}
}
public static class MyIgnorePolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
doLog(r, e);
}
private void doLog(Runnable r, ThreadPoolExecutor e) {
// 可做日志记录等
System.err.println( r.toString() + " rejected");
// System.out.println("completedTaskCount: " + e.getCompletedTaskCount());
}
}
static class MyTask implements Runnable {
private String name;
public MyTask(String name) {
this.name = name;
}
public void run() {
try {
System.out.println(this.toString() + " is running!");
Thread.sleep(3000); //让任务执行慢点
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public String getName() {
return name;
}
public String toString() {
return "MyTask [name=" + name + "]";
}
}
}
线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这
样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
- 1) FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。 - 2) CachedThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
FutureTask
用于异步获取执行结果或取消执行任务。通过传入Callable给FutureTask,直接调用run方法执行,之后可以通过FutureTask的get异步方法获得执行结果。FutureTask即使多次调用了run方法,它只会执行一次Callable任务,当然也可以通过cancel来取消执行。
《分布式java应用》P158
ArrayBlockingQueue
基于数组、先进先出、线程安全的集合
CopyOnWriteArrayList
线程安全,读操作时无锁的ArrayList。每次新增一个对象时,会将创建一个新的数组(长度+1),将之前的数组中的内容复制到新的数组中,并将新增的对象放入数组末尾。最后做引用切换。
CopyOnWriteArraySet
与上面的类似,无非在add时,会调用addIfAbsent,由于每次add时都要进行数组遍历,因此性能会略低于CopyOnWriteArrayList
ReentrantLock
单锁。控制并发的,和synchronized达到的效果是一致的。
Lock方法,借助于CAS机制来控制锁。
Unlock方法,释放锁
ReentrantReadWriteLock
与ReentrantLock没有任何继承关系,提供了读锁和写锁,在读多写少的场景中大幅度提升性能。
持有读锁时,不能直接调用写锁的lock方法
持有写锁时,其他线程的读或写都会被阻塞。
ReentrantReadWriteLock lock=new ReentrantReadWriteLock();
WriteLock writeLock=lock.writeLock();
ReadLock readLock=lock.readLock();
《分布式java应用》P165
如何避免死锁
制定锁的顺序,来避免死锁(先A后B,避免A->B和B->A同时存在);
尝试使用定时锁(lock.tryLock(timeout))
在持有锁的方法中进行其他方法的调用,尽量使用开放调用(当调用方法不需要持有锁时,叫做开放调用)
减少锁的持有时间、减小锁代码块的粒度。
汇总


